Some words of encouragement from a Senior Manager for Data Science

Maybe you’ve read about the huge tech layoffs, or experienced the job market recently? Or perhaps you’ve seen a few headlines or read some articles on LinkedIn, or your family have been asking you why you’re needed now that everyone has ChatGPT…
It can sometimes feel like Data Science is dead – or at least dying.
So: What’s going on?
Time was, you could claim to be a Data Scientist if you were somebody who rattled around in a Jupyter notebook, did some 🐼🐼🐼 munging, spit out a few seaborn 📈 or – whoop! – a Plotly Dash app, plugging away at a nice handful of csvs, gleaning insights that your stakeholders had never had before from their tired, dusty, flat data. A bit of causal inference via feature importance on a Random Forest classifier went a long way when some of the engineers’ kids were born pre-decimalisation. Perhaps you’re at a company where databases are witchcraft, and siloed Excel sheets are still the plat-du-jour. Some ETL, a quick sklearn pipeline to do some hyper-parameter tuning, whip up a truth table, and BAM: you’ve got the SLT/C-suite’s attention…
Just better hope the excel sheets don’t change too much for next month…
FAANG have all the fun - at a cost!

But… and I say this with love… a lot of this is just (admittedly quite advanced) data analysis. It isn’t necessarily predictive, but actually ‘just’ descriptive – giving solid evidence for sometimes outside-the-box thinking, on historical events.
Yes, with some interpretation by a domain expert it could allow for some predictions, but it isn’t the FAANG customer segmentation/predictor models which keep you hooked, scrolling or buying.
IT CAN’T BE - those companies live and breath data. Their systems are built to capture more data. They are basically data companies! This is kind of why they freak us out a bit — how much they know about us – but it’s also the reason their machine learning engineers get to work on and deploy some seriously fun, powerful, value-adding models. A strong foundation of bountiful, good quality data, driven by an understanding that nailing collecting the right data will allow them to gain traction, build value, grow the user base… wash-rinse-repeat. The product is deployed to be interacted with and log all of that information; arguably the data IS the product – it’s just the user is not the customer.
Lots of other companies: “Why can’t we do that??”
Since 2010 I’ve worked in science or engineering companies and consultancies where I interfaced with dozens of client companies, ranging from SMEs to huge multinationals - the problem is systemic and ubiquitous.
Too many businesses have, for too long, considered data capture almost as an after-thought to their main aim, a nice to have, a bonus – like you might collect random extra screws from IKEA furniture… “sure, it will be of value, but we’ll sort it another day”. I’ve seen data ‘logged’ for product control, manufacturing, or characterisation, in non-automated and non-scalable ways. Network drives full of csvs; groups reliant on sharepoint libraries of excel files; or teams which use their Teams’ chats to dump data analysis outputs - even raw and aggregated files… They are barely digitialised in the proper sense, and hence these companies are poorly set up for out-of-the-box data science, the implementation of ML or AI.

The CXO have been getting wise to the issue for some time, and realise that ML/AI can be used to supercharge their business: to improve forecasts, optimise processes, operations, inventory, shift patterns – whatever.
Some businesses are turning to vendors who offer off-the-shelf solutions to power their predictive analytics and AI strategies. Indeed for some industries (including the one I’m in) there are go-to software solutions which are now incorporating ML and AI out-of-the-box, or bolt-on modules for more legacy systems. And more and more we see general platforms are offering ‘AI-augmented’ capabilities (I’m looking at you CoPilot!).
Data scientists (or data-literate people) can play a huge role in helping businesses integrate and implement such systems, or as part of a wider data-democratisation piece.
However: data science, machine learning, AI – whether being developed from the ground-up internally, or using a purchased system – they are the cherry on the cake; by definition requiring a ‘cake’. What is this cake?
DATA
Consistent (ha), clean (lol), neat (loller), reliable (ok stop), live (FFS), high resolution data, logged automatically, into a database, and ready to access
CXO: So… we need some data scientists!?
Well - yes and no. I feel like the term “data scientist” could/has become an umbrella phrase for all of the nuanced roles which reside within the sphere of ‘data analytics and predictive analytics’, even encompassing data engineer. A general data strategy is required, and it would be wise, in development of that, to have some key data personnel involved:
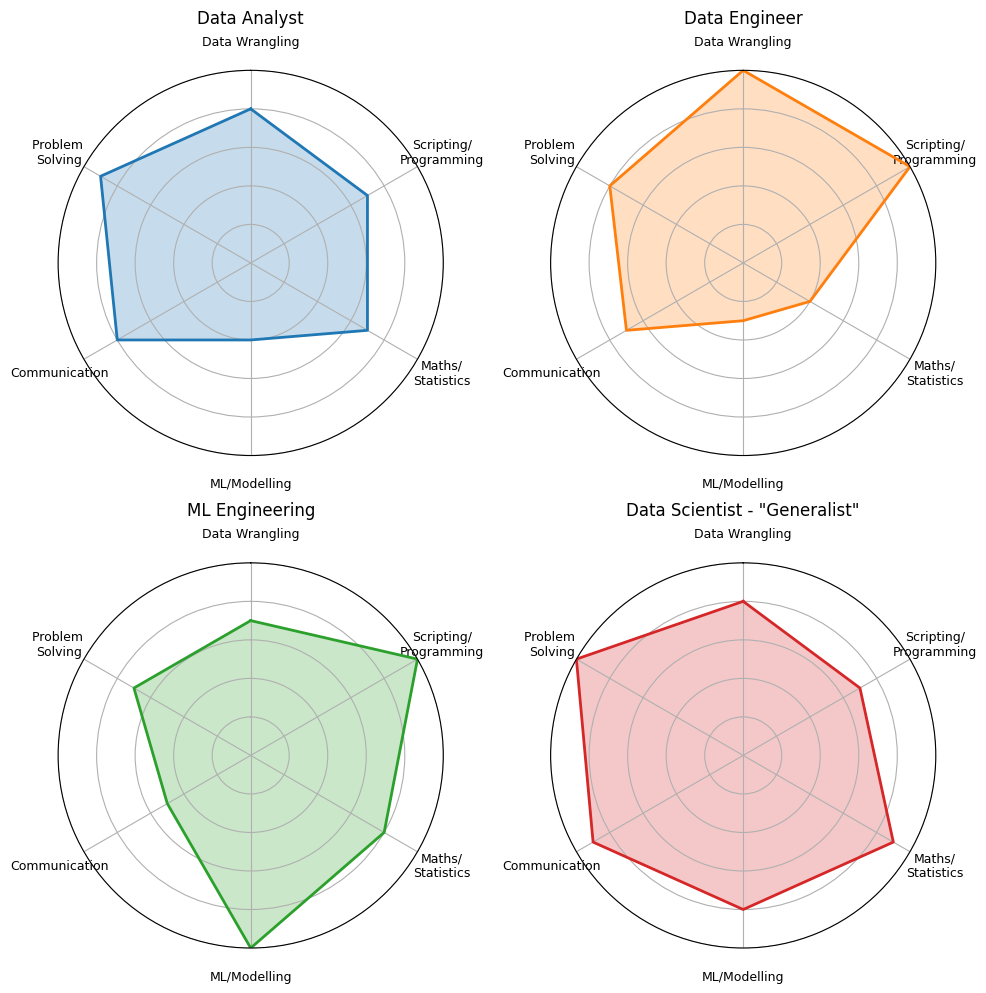
These radar plots aim to demonstrate and differentiate skillsets that the various roles within a data team may possess and specialise in (the list is not exhaustive). You may or may not agree with this breakdown – it’s anecdotal and based on my experience – but hopefully it makes the point of the core competencies required for the various roles. It also shows the huge degree of overlap between the roles.
What it doesn’t really allude to though is that, at different stages of a businesses growth, you need to lean heavily into those skills by differing amounts
- A well established business which has 50 years of ledgers and 100 TB of files on hard drives containing all of their customer data, manufacturing records, IP … They’re going to need a Head of Data (or Digitalisation?) and likely a couple or even small team of data engineers to begin sorting out the infrastructure.
- A tech start-up formed 10 years ago is probably already on the cloud, and is 99% database driven: Data Scientist/ML Eng head-count green light!
Why The Fall From Grace
I feel like the hype around Data Science some years back has been driven by the worrying misconception that most businesses collect data how Google or Amazon might, using industry-defining best practises; normalised database tables following the Kimble model, APIs to interact with various data-logging systems, well documented code and database schema.
Hahaha.
Let’s review the situation to understand, and try and apply some context:
- Data science relies on a strong data infrastructure and data-centric culture; this takes time to get right, and requires budget, resource, and CXO buy-in (ideally CXO-led!)
- The fables of a DS team deploying some sexy value-adding models that turn a company’s fortune around over-night are rare (read: complete bollocks)
On top of all of this, the softer, tertiary factors to consider include:
- Reported salaries are a bit nuts (thanks FAANG – $450k at Netflix… for the median?!)
- COVID hit us all like a brickwall…
- which has been conflated by the move to remote work…
- against which there is now a significant backlash
- which has been conflated by the move to remote work…
- There are some awful wars going on, a tanking economy and significant geopolitical instability; companies are risk averse and trimming headcount as a result
- The deployment of various GenAI platforms is rapidly improving everyone’s ability to write (or vibe 🤮) code and “understand” their data better (no it’s not, but it feels like it)
- so Data Scientists can be seen as a luxury
What should you do about this?
The job market waxes and wanes - that’s the nature of life. But be prepared for what the market needs by:
- keeping up-to-date with relevant skills - GenAI isn’t going anywhere, so get involved and learn where they hype ends and the value begins
- building a project portfolio is great, especially if you can walk someone through some examples… and, crucially:
- assume you won’t be handed a clean dataset - or maybe even data at all! The thousands of data science/ML/AI/next-big-thing degrees and courses need to stop cutting to the chase, and focus on the basics.
Data Engineering
Sometimes your data won’t be collected in a database; learn how to resolve this - look into best practises around data engineering, and become proficient with the basics of:
- ETL including by scripting & scraping
- data models including the star schema
- SQL!! NON NEGOTIABLE
- Basics of linux CLI commands
- Git (because accidents happen)
On prem or on-cloud - knowing the basics of these skills will get you a long way.
Communication is KEY
I would say being able to communicate well is one of those really under-rated skills (generally!). Just think back to your teachers - you’ll remember the good ones.
To listen and to explain well is almost an art, and it’s a key capability to demonstrate in any interview - certainly for technical topics, which data science absolutely qualifies as.
- How confident and comfortable are you at discussing your own experience, or explaining project you’ve delivered and really enjoyed?
If you’re faltering on such familiar ground (nerves, of course, can be understood), then that is something to work on.
Taking it further, when dealing with developing a project, stakeholders won’t always understand the intricacies of what they’re asking of you; be it a model, or dashboard, or some analysis. It’s your job to help guide that conversation, which can sometimes mean posing quite challenging questions.
On the other hand, some stakeholders will want to know how the data collection/pipeline needed to be improved to help with expectations next time. They may want to understand:
- the weightings of a certain model
- how you tuned some parameters and what this means
- how a dashboard or even some model interface can be modified for additional functionality…
so get used to explaining the output and technical details in a way a non-coder can understand. It is, after all, their baby too!
Final Thoughts
Data Science, or rather the role of the data scientist, is evolving. Expect it to continue to do so.
It was long overdue a correction, or reality check - a much-needed refinement of a nascient field, bloated with recruits, and under enormous pressure to deliver on hyped-up expectations. Sounds familiar.
It could not be expected to deliver the promised gains for the huge swathe of businesses that aren’t fully digitalised.
However! To the people who have invested their time and money in their passion for data, who have developed their skills to understand statistics & coding, modelling, plotting, dashboards… there is PLENTY still to do, opportunities abound, and I don’t see that going away any time soon.
Evolve your skills, and update your pitch; you’re a problem solver who knows advanced coding and statistics. That’s a heady combination. As a data scientist, you’re working across a stack of skills and capabilities. If you can own and enable each part, or at least more parts, of the data –> insight pipeline and process, and understand the broader context of the puzzle you’re trying to solve, you’re of incredible value.