In Part 1 of this two-parter on data team efficacy, I wrote about what a data team typically does, and as a result what sorts of roles make up a data team; it covered organisational, analytical, and administrative roles - accounting for ownership of the structure and usage of data. In this post I want to outline my thoughts on the structures of a data team WITHIN an organisation - because getting this right is key to empowering the entire business with ready access to data, fast analytics, scalable infrastructure and - ultimately - driving the ROI.

The Matrix Model
Or the cross functional approach. Or ‘horizontally aligned’. There’s a few names, but it boils down to the same: data professionals (engs, analysts, scientists) are embedded across the different departments. In some business this will be how the project management or HR functions are distributed - where you have a dedicated OPS HR team, or specific Product PMO lead. The data team similarly don’t report in to a single business line, but instead supports multiple teams in parallel.
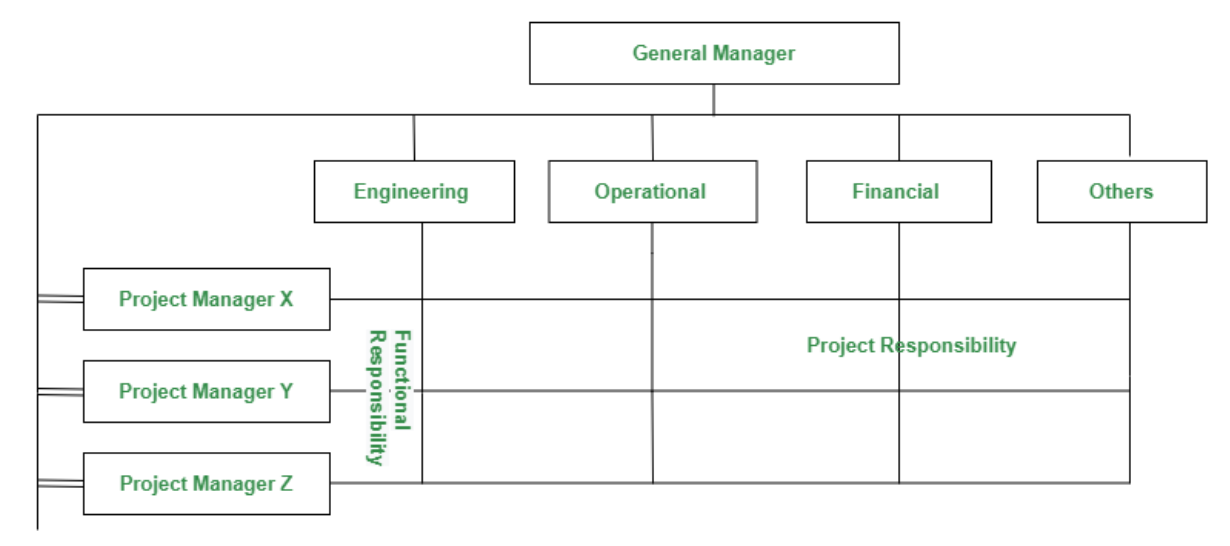
This can be really a powerful route for the following reasons…:
-
Close proximity to a specific business unit means the data scientists can learn more about - and act on - domain specific challenges
-
Analysts are constantly working on relevant and actionable business problems
-
Iteration cycles and deployment can be faster due to them having closer alignment with stakeholders and generally better domain knowledge
However:
-
Being decentralised means a problem solved in one division might be resolved, separately in another
-
Tools, documentation, standards etc. can all diverge from other data specialists, without strong, cohesive technical leadership
-
Mentorship and progression may suffer as there could be conflicting line management (from any technical lead vs. business leadership
2. The Standalone Model
Or centralised, or vertically integrated model, is one where the data team functions as an independent unit, possibly under a CDO or CIO alongside IT, or maybe within Strategy, or OPS or Technology.
The team handles requests from various departments, prioritising work based on organisational goals. Again, this can be the favoured approach due to:
-
Consistency of tools, standards, and models, allowing for excellent documentation and quality control
-
Visibility of the various objectives across the company and data-led endeavours affords greater efficiencies, with less duplication of efforts
-
Much improved shared learning, mentoring, and a clear career path
… but as ever, there are downsides:
-
Detachment from business means that that data teams may miss important context and can feel siloed
-
A central team can become overwhelmed with requests, leading to delays, alongside the political challenge of prioritising various tasks, to the detriment of certain projects or business units
-
Lack of significant domain exposure can mean a slower pace of interaction, with subject matter expertise taking time to develop
3. Hybrid and Evolving Models
I’ve seen both approaches used. In my experience, the matrix approach’s biggest detractor is the confusion when poor communication or coordination inevitably happens and, for example, multiple analysts work on the same/similar projects, missing huge efficiency opportunities. Frequent alignment meetings across the technical data teams is ESSENTIAL to mitigate this.
The standalone approach faces the key issue of allowing a data-team to get siloed and out-of-the-loop, and possibly under- or poorly-utilised. On the flip side they could become a bottleneck due to conflicting priorities. Embedding, sharing code and domain knowledge and rotating through teams helps here, so long as it’s managed fairly.
All of this speaks to some form of hybrid organisational approach, where elements of both are used. For instance, a central data team might own core infrastructure, data governance, and ML platform development, while embedded analysts or scientists are assigned to business units for specific projects, and to develop subject matter expertise.
This can lead to the best of both worlds: strong governance from the centre, and tight alignment with business needs at the edge.
For this to work though, some points to note:
-
There need to be clear roles, as well as definitions for what is owned, where and by whom
-
Frequent cross-functional stand-ups and technical review boards are crucial in helping coordinate work and maintain standards
-
Letting data staff rotate between central and embedded roles to promote knowledge sharing and expose the wider company to the various members of the team - it’s a 2-way issue
Final Thoughts
As you can probably infer, there isn’t a one-size-fits-all solution; all companies are different, and the “best” structure depends on your organisation’s size, maturity, leadership culture, and business model.
A startup might benefit from embedded analysts sitting with product teams, while an enterprise needs to prioritise governance and scalability.
The key is clarity of goals, ownership, and communication; with these in place the data function can thrive, regardless of structure.